¿Que es el robots.txt?
El robots.txt es un pequeño pero vital archivo que nos permite indicarle a los bot de los buscadores como deben rastrear nuestra página cuando accedan a la misma.
Es decir, cuando el bot de Google o de Bing o de cualquier otro buscador llegan a nuestra página lo primero que hacen es ir a nuestro archivo robots.txt y seguir las indicaciones que le damos en el mismo.

Cabe decir que su existencia no es obligatoria. Si no incluimos un robots.txt o este no tiene el formato adecuado, los bot entenderán que tienen libre acceso a todo el sitio web.
El archivo utiliza el Estándar de exclusión de robots, un protocolo con un conjunto de comandos que se puede utilizar para indicar el acceso al sitio web por sección y por tipos específicos de rastreadores web.
El archivo robots.txt tendrá que tener expresamente éste nombre y ser colocado en la raíz del dominio. Y por su propio naturaleza deberá ser accesible a todo aquel que quiera ver su contenido. Si quieres ver el archivo robots.txt de una web lo único que tienes que hacer es escribir algo como dominio.es/robots.txt El mío, por ejemplo, está en waukin.es/robots.txt
Un aspecto a tener en cuenta es que un bot puede ignorar completamente las indicaciones del robots.txt. Los buscadores tienden a obedecer lo que les indicamos pero lo normal es que otros bot no le hagan demasiado caso. Y eso es especialmente cierto en el caso del malware.
Simplemente el robots.txt no tiene utilidad como medida de seguridad ni es una buena manera de mantener una información privada. Si ese es nuestro objetivo lo mejor sería proteger el directorio con una contraseña en el .htaccess o algún método equivalente.
Hay que tener en cuenta que el robots.txt solo funcionará en el dominio en el que expresamente se encuentre alojado. No funcionará con los subdominios que creemos y tendremos que generar un nuevo robots.txt para cada uno de ellos. También necesitarán su propio archivo cada puerto y cada protocolo que queramos bloquear.
Por ejemplo, si yo creo un subdominio que se llame files.waukin.es el archivo waukin.es/robots.txt no tendrá ningún efecto cuando el Googlebot rastree la página files.waukin.es Para ello deberé crear un nuevo archivo en files.waukin.es/robots.txt
Crearlo es algo bastante sencillo. Simplemente necesitaremos un bloc de notas, abrir un nuevo documento, añadir las directivas que estimemos oportunas y guardarlo como robots.txt. Sin más misterio. Eso sí, es aconsejable guardarlo con una codificación UTF-8. Luego basta con subirlo a la raíz del dominio vía ftp.
Entendiendo la estructura del robots.txt
Los operadores
Como ya hemos comentado el robots.txt respeta el “Estándar de exclusión de robots” y eso incluye sus reglas de sintaxis a la hora de escribir el documento. Las reglas que deberemos tener en cuenta son las siguientes:
- Debes respetar las mayúsculas/minúsculas, la puntuación y los espacios. En el robots.txt no es lo mismo indicar /wp-content que /WP-content
- Cada grupo User-agent/Disallow debe estar separado por una línea en blanco. En caso contrario se entenderá que las directivas son de aplicaciones a todos ellos. (esto lo veremos más adelante)
- Podemos incluir comentarios colocando una almohadilla (#) al comienzo de una línea. Sería conveniente comentar en primer lugar la fecha del archivo para tener un control de versiones. También sería conveniente comentar cada modificación que realicemos indicando la fecha correspondiente de cara a conocer la razón de la misma.
Además, podremos utilizar dos expresiones regulares para identificar las páginas o subcarpetas que deben respetar las directivas de nuestro archivo:
- El asterisco (*) – Es un comodín que representa cualquier secuencia de caracteres. No se deberá utilizar al final de la directiva ya que se entenderá implícitamente que al final de la misma será valido cualquier carácter. Si por ejemplo indicamos /*.pdf nos estaremos refiriendo a todos los archivos que contengan .pdf. Y valdrá tanto para waukin.es/document.pdf como para waukin.es/document.pdf?ver=1.1
- El símbolo del dólar ($) – Indica como debe finalizar forzosamente la URL indicada en la directiva. Si existiese algún carácter después de dicho símbolo no se aplicará la misma.Si por ejemplo indicamos /*.pdf$ nos estaremos refiriendo a todos los archivos que terminen con un .pdf. Esto incluye a waukin.es/document.pdf pero excluye a waukin.es/document.pdf?ver=1.1
El User-agent
Lo primero que deberemos hacer en el robots.txt es definir a que bots nos estamos dirigiendo. Para ello indicaremos en una línea el User-agent. Así por ejemplo si queremos que las directivas siguientes solamente se apliquen a los bot del buscador de Google deberemos indicar:
User-agent: Googlebot
Si quisiésemos que se aplicase unicamente al bot de Bing indicaríamos:
User-agent: MSNBot
Justo después de la línea de User-agent indicaremos las diferentes directivas que deberán obedecer los bot que accedan a nuestra web. Si justo debajo de un User-agent indicamos otro más sin dejar ningún espacio en blanco entre medias, estaremos indicando que las directivas deben ser aplicadas a ambos.
Por ejemplo, de esta manera:
User-agent: MSNBot
User-agent: Googlebot
Ahora estamos indicando que todas las directivas que se coloquen bajo estos dos User-agent se aplicarán tanto a los Bot de Google como a los de Bing. Si dejásemos un espacio en blanco las directivas solamente se aplicarían al último User-agent, teniendo el otro acceso libre a todo el sitio.
También podremos utilizar el símbolo de asterisco si lo que queremos es que un conjunto de directivas se apliquen a todos los bot que accedan a nuestra página.
User-agent: *
Otro aspecto a tener en cuenta es que cada Bot obedecerá unicamente a lo que indique un único User-agent, siendo este el más específico de ellos. Si por ejemplo, solamente definimos el User-agent para Googlebot todos los bot de Google lo obedecerán. Sin embargo, si especificamos un User-agent para Googlebot y un User-agent para Googlebot-Image, Googlebot-Image ignorará todas las directivas bajo el User-agent de Googlebot.
En el siguiente ejemplo estaríamos permitiendo el acceso a los bot de Google menos al de imágenes y bloqueando a todos los demás bots.
# Bloqueamos el acceso a todos los bot
User-agent: *
Disallow: /
#Permitimos el acceso a toda la página a Googlebot que seguirá este User-agent en lugar del anterior al ser este más específico.
User-agent: Googlebot
Disallow:
#Bloqueamos el acceso a toda la página a Googlebot-Image que seguirá este User-agent en lugar del anterior al ser este más específico.
User-agent: Googlebot-Image
Disallow: /
Entendiendo las directivas del robots.txt
Directiva Disallow
Esta directiva nos permite indicar a los bot que NO rastreen la página. Y digo rastrear, no indexar. Porque indexar si que pueden.
Digamos por ejemplo que yo establezco en mi robots.txt algo como Disallow: /categorias/ Bien, los bot no van a rastrear la url waukin.es/categorias/ y por lo tanto no van a conocer su contenido. Pero si un buscador considera que dicha página es relevante debido a la calidad o cantidad de enlaces entrantes, o cualquier otro factor, si que va a indexarla. Pero eso sí, no indexará su contenido.
Por ejemplo, Google puede indexar la página pero en las SERP la mostraría indicando en el snippet el mensaje: No hay disponible una descripción de este resultado debido al archivo robots.txt de este sitio. También puede ocurrir que el buscador nos devuelva en la consulta la URL incluyendo en el snippet la descripción del ODP o del directorio de Yahoo. Aunque esto es cada vez más improbable.
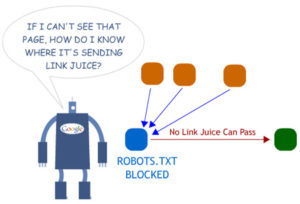 Además, Disallow tampoco evita el traspaso de link-juice. De hecho si tienes enlaces entrantes dicha página recibiría el link-juice de los mismos pero como el bot no rastrea su contenido no lo traspasaría a su vez a las páginas que la tuviesen enlazada.
Además, Disallow tampoco evita el traspaso de link-juice. De hecho si tienes enlaces entrantes dicha página recibiría el link-juice de los mismos pero como el bot no rastrea su contenido no lo traspasaría a su vez a las páginas que la tuviesen enlazada.
Siguiendo con el ejemplo anterior, pongamos por caso que desde waukin.es pongo un enlace a waukin.es/categorías/. Y desde waukin.es/categorias/ pongo otro enlace a waukin.es/servicios/.
waukin.es/categorías/ recibiría el link-juice de waukin.es pero no lo traspasaría a waukin.es/servicios/ simplemente porque como el bot no puede rastrear la página no sabe que ese enlace existe.
Por lo tanto, con la directiva Disallow evitamos que se rastree un contenido determinado pero no evitamos necesariamente la indexación de la página. Además, no es la mejor manera de distribuir nuestro link-juice por nuestra web.
Ejemplos de uso de la Directiva Disallow
Vamos a ver unos ejemplos para ilustrar el funcionamiento de las directivas y los operadores en el archivo robots.txt. En este caso con la Directiva Disallow. No obstante, los ejemplos son extrapolables a otras directivas ya que la sintaxis y los operadores funcionan de manera similar en todas ellas.
Supongamos que queremos bloquear el acceso de los bot a la totalidad de la página. En este caso utilizaríamos:
Disallow: /
Si por el contrario le queremos permitir el acceso total de un bot a la página no deberemos escribir nada después de la directiva Disallow:
Disallow:
Pongamos que queremos bloquear todas las páginas que comiencen su URI con “contenidobloqueado”. Un ejemplo correcto sería:
Disallow: /contenidobloqueado
Esto bloquearía todas las URL que empezasen por /contenidobloqueado tales como:
- midominio.es/contenidobloqueado.html
- midominio.es/contenidobloqueado/
- midominio.es/contenidobloqueado-imagenes/background
En cambio y teniendo en cuenta lo que hemos explicado en el apartado anterior no bloquearía las URI que no comenzasen exactamente por contenidobloqueado como por ejemplo:
- midominio.es/index/contenidobloqueado
- midominio.es/imagenes-contenidobloqueado
Para ello deberíamos utilizar el operador de asterisco de la siguiente manera:
Disallow: /*contenidobloqueado
Esto si bloquearía el acceso a todas las URL que contengan contenidobloqueado independientemente de su posición dentro de la misma. Como por ejemplo:
- midominio.es/contenidobloqueado.html
- midominio.es/contenidobloqueado/
- midominio.es/contenidobloqueado-imagenes/background
- midominio.es/index/contenidobloqueado
- midominio.es/imagenes-contenidobloqueado
Si en cambio lo que queremos es bloquear la carpeta de contenidobloqueado deberemos colocar una barra lateral al final de la directiva de la siguiente manera:
Disallow: /contenidobloqueado/
De esta manera bloquearemos todas las URL que contengan dicha carpeta al comienza de la URI como por ejemplo:
- midominio.es/contenidobloqueado/
- midominio.es/contenidobloqueado/imagenes/
En cambio, no bloquearíamos aquellas URL que no contengan exactamente esa carpeta o que no la contengan al comienzo, como por ejemplo:
- midominio.es/contenidobloqueado.html
- midominio.es/contenidobloqueado-imagenes/background
- midominio.es/index/contenidobloqueado
- midominio.es/imagenes-contenidobloqueado
Si quisiésemos bloquear todas las URL que contengan /contenidobloqueado/ independientemente de su posición en la misma deberíamos utilizar la directiva de la siguiente manera:
Disallow: /*/ contenidobloqueado/
en este caso permitiríamos tanto:
- midominio.es/contenidobloqueado/
como
- midominio.es/index/contenidobloqueado
Si en cambio queremos bloquear toda página html que contenga contenidobloqueado en su URL deberíamos indicar algo como:
Disallow:/*contenidobloqueado*.html
Para bloquear el acceso a una página html que finaliza en contenido bloqueado deberíamos escribir en nuestro robots.txt:
Disallow:/*contenidobloqueado.html
Si lo que deseamos es bloquear todas las URL que finalicen en contenidobloqueado deberíamos utilizar:
Disallow: /* contenidobloqueado$
Directiva Allow
Aunque la directiva Allow está lejos de ser una directiva estándar, es respetada por la mayor parte de buscadores como Bing, Google o Yandex. Su función es justamente la inversa a Disallow e indica a los bot un contenido que puede ser rastreado por los mismos.
Debemos de tener en cuenta que si no restringimos previamente un contenido con Disallow los bot entenderán que tienen libre acceso al mismo sin necesidad de utilizar la directiva Allow. Por tanto utilizaremos Allow únicamente cuando queramos permitir el rastreo de un recurso o una serie de los mismos que previamente hayan sido bloqueados por la directiva Disallow.
Pongamos por ejemplo que utilizamos Wordpress y decidimos bloquear la carpeta /wp-content/plugins/ pero resulta que no queremos bloquear los archivos .css y .js dentro de la misma. Para ello utilizaremos las siguientes directivas:
Disallow: /wp-content/plugins/
Allow: /wp-content/plugins/*.js
Allow: /wp-content/plugins/*.css
De esta manera no bloquearemos el acceso a los archivos .js y .css ya que el bot obedecerá al acceder a cada archivo únicamente a una y sólo una de las directivas indicadas. Hay que tener en cuenta que los diferentes bot de Google tendrán en cuenta la directiva que contenga más caracteres.
Así por ejemplo en el ejemplo anterior accederán a los archivos .css ya que la directiva que lo permite es /wp-content/plugins/*.js y esta tiene más caracteres que la directiva /wp-content/plugins/ la cual restringiría el acceso a dicho directorio.
Si en su lugar indicásemos en nuestro archivo robots.txt las siguientes directivas:
Disallow: /wp-content/plugins/
Allow: /*.js
Allow: /*.css
Los archivos .js y .css que estuviesen dentro del directorio /wp-content/plugins/ seguirían bloqueados ya que la directiva Disallow tiene más caracteres que las directivas Allow indicadas en el ejemplo.
Tampoco es recomendable desbloquear el acceso a nuestros archivos .js y .css indicando unas directivas del tipo:
Allow: /wp-content/plugins/*.css$
Allow: /wp-content/plugins/*.js$
En este último caso estaríamos indicando que para ser desbloqueados los recursos y permitir el acceso de los bot deben forzosamente terminar en .js y .css. Es decir, si el recurso tiene algún parámetro en la URL como por ejemplo en http://fonts.googleapis.com/css?family=Comfortaa:300 , seguiría bloqueado el acceso.
Directiva Noindex (experimental) - Obsoleta desde el 01/09/2010
Actualización Importante: Desde el 01/09/2019 Google ya no da ningún tipo de soporte a la directiva Noindex. Así que es completamente inútil emplearla. Lo más conveniente es eliminarla completamente del robots.txt.
Lo primero que hay que dejar muy claro sobre la directiva Noindex es que se trata de una directiva experimental a la cual Google no le da soporte de manera oficial. Dicho de otra manera, os voy a contar como funciona en base a mi experiencia y a un puñado de artículos que corren por la red pero teniendo en cuenta que en el futuro puede no funcionar.
Nadie debería basar su estrategia de  rastreo únicamente en esta directiva. En cualquier momento Google puede decidir dejar de darle soporte (experimental). Y podría hacerlo sin previo aviso y sin emitir ninguna comunicación pública.
rastreo únicamente en esta directiva. En cualquier momento Google puede decidir dejar de darle soporte (experimental). Y podría hacerlo sin previo aviso y sin emitir ninguna comunicación pública.
Como hemos comentado la directiva Disallow impide el rastreo pero no la indexación. Google puede seguir indexando una URL bloqueada con Disallow si estima que puede ser relevante debido, principalmente, al número de enlaces entrantes que recibe.
La directiva Noindex permite evitar el rastreo y además también impide la indexación de la URL. Es una forma más eficiente de controlar como se muestra nuestra página en las SERP de Google.
En principio Noindex podría ser utilizado en solitario sin acompañarlo de Disallow. Pero sería conveniente utilizar ambas directivas en conjunción en previsión de la posibilidad de que Google deje de darle soporte en un futuro.
Así por ejemplo podríamos utilizarlo de la siguiente manera:
Noindex: /wp-admin/
Pero sería más prudente utilizarla como:
Disallow: /wp-admin/
Noindex: /wp-admin/
Otras Directivas
En primer lugar nos encontramos con la directiva Sitemap. Nos permite indicar la ubicación del sitemap de nuestra web de cara a que sea más fácil de rastrear para los bot. Esta directiva es la excepción que confirma la regla y no se aplica a ningún User-agent en concreto, siendo en cambio aplicable a cualquier bot.
También nos encontramos con la directiva Crawl-delay, la cual limita la velocidad de rastreo de nuestra web por parte de los buscadores. Crawl-delay tampoco es estándar y de hecho es completamente ignorada por los bot de Google. En cambio los bots de otros buscadores como Bing o Yandex si que la tienen en cuenta.
Hay muchas más directivas ya que cada buscador tiene unas especificaciones diferentes. Así podremos encontrarnos con las directivas Host o Clean-param. Pero las expuestas anteriormente suelen ser las más comunes y suficientes para nuestro robots.txt.
De todas maneras y si pretendemos posicionarnos en un buscador diferente a Google deberíamos repasar la documentación oficial del mismo para conocer sus especificidades. Esto es especialmente recomendable en el caso de Yandex.
Ejemplo de un archivo robots.txt
Aquí podéis ver el robots.txt de esta página web. Obviamente también podéis verlo, como ya comentamos al principio del post, navegando hacia waukin.es/robots.txt Lo he comentado debidamente y creo que ilustra bastante bien lo expuesto anteriormente.
Se trata de un ejemplo y no es recomendable que lo utilices en tu propia página web. Podrías bloquear bastantes recursos o que no te sirva absolutamente para nada. No deberías ni siquiera utilizarlo como guía. Es simplemente un ejemplo de lo expuesto a lo largo del post.
#Versión 1.0 del 20/11/2018 por Jose Antonio Neto https://joseantonioneto.esUser-agent: *#Añadido por Yoast por defectoDisallow: /wp-admin/Allow: /wp-admin/admin-ajax.php#Bloqueamos acceso a busquedasDisallow: /*?s=Sitemap:https://waukin.es/sitemap_index.xml
Consejos y recomendaciones
Un primer consejo es utilizar el probador de robots.txt de Google Search Console. En él podemos ver la versión que tenemos subida a nuestro servidor del robots.txt. También podremos comprobar si efectivamente se bloquean las URL deseadas o si tenemos errores de sintaxis en el archivo.
Pero lo más interesante es que podremos escribir nuevas directivas en el probador de robots.txt, comprobar si efectivamente funcionan y descargar un nuevo robots.txt con las modificaciones realizadas. De esta manera reducimos el riesgo de errores en nuestro archivo.
Una vez lo subamos al servidor Google tardará un día aproximadamente en descargar la nueva versión. Si no queremos esperar podemos forzar a Google a descargar la versión actualizada haciendo clic en enviar.
Otro aspecto muy importante es la utilización del robots.txt en sitios de comercio electrónico. Especialmente si utilizas mucho ajax en tu web por ejemplo en filtros, botón de añadir carrito, buscador, etc...
Si bien es cierto que Google realiza un gran esfuerzo en entender javascript, sigue teniendo problemas para rastrear correctamente este tipo de enlaces. En muchos casos esto genera un problema de contenido duplicado ya que no interpreta correctamente las Url con parámetros en las mismas.
Así que es preferible bloquear, en la mayor parte de los casos, las URL con parámetros utilizando Disallow y Noindex en nuestro robots.txt Como ya hemos comentado si solamente utilizamos Disallow, todavía pueden aparecer en las SERP
Un último consejo sería no utilizar el archivo robots.txt si no entendemos bien su utilidad o sus directivas. Un mal uso del robots.txt puede provocar que no se indexe correctamente nuestra página web. En román paladino, podemos no aparecer ni de coña en las búsquedas.
La verdad es que la mayor parte de los sitios web, en especial blogs o páginas de pequeña empresas, tienen una estructura lo suficientemente sencilla como para que los buscadores la rastreen sin problemas.
Simplemente en muchos casos no es necesario utilizar el robots.txt pero utilizarlo mal puede provocar problemas muy graves. Si pese a todo quieres utilizarlo y no tienes claro como, te recomiendo contratar a un profesional.
Consideraciones finales
El archivo robots.txt es una herramienta muy potente. Nos permite orientar el rastreo de los bot de manera eficiente. Si evitamos que los bot pierdan tiempo rastreando recursos no relevantes para el usuario, conseguiremos que dediquen una mayor frecuencia de rastreo a los contenidos que nos interesa posicionar. Y eso suele traducirse en una mejor posición en las SERP.
Y si bien es cierto que hay mejores formas de evitar el contenido duplicado y la indexación (o desindexación) de contenidos en los buscadores, no es menos cierto que algunas veces no nos queda otra alternativa. Como por ejemplo el caso de los filtros ajax que generan muchos CMS.
Pero no debemos de perder de vista que nuestro objetivo es aparecer en los buscadores. Un mal uso o un error grave en nuestro robots.txt puede dañar gravemente nuestro posicionamiento. Deberemos tener muy clara cada directiva empleada en nuestro archivo, su validez y sus consecuencias. Y en caso de duda, mejor no hacer nada.




