¿Que son las meta robots tag?
Al igual que el robots.txt, las META etiquetas robots son un estándar de facto. Su origen se sitúa en un seminario de indexación del año 1996 en cuyas notas se describe su funcionamiento. Posteriormente las META etiquetas se describieron en las especificaciones del HTML 4.01, Apéndice B.4.1.
La etiqueta META Robots nos permiten indicarle a los robots de los motores de búsqueda como deben procesar nuestra página web cuando la visiten. Podremos indicarles si un documento debe ser indexado o seguido para obtener más enlaces.

Cada una de las páginas de nuestro sitio puede tener una etiqueta meta robots distinta o incluso no tener ninguna. De esta manera podremos definir de manera independiente cómo deseamos que se trate cada una de las páginas que componen nuestra web.
Las META robots deben ser colocadas dentro del <head> del documento html. Una buena práctica sería colocarla al principio del documento para permitir que los bot puedan rastrearla lo antes posible.
Obviamente, si lo que pretendemos es evitar que se indexe un documento tipo .pdf o .doc esta solución no nos va a servir. Simplemente no hay un <head> dentro del cual colocar ninguna META. La solución a esto es utilizar las X-Robots-Tag.
Las X-Robots-Tag deben ser colocadas dentro de la cabecera HTTP y funcionan de una manera equivalente a las META etiquetas robots. Deben ser implementadas a nivel de servidor. Si por ejemplo, nuestro servidor es Apache podremos hacerlo a través del archivo .htaccess
Un detalle a tener en cuenta es que no todos los buscadores soportan las X-Robots-Tag. Bing y Google si las tienen en cuenta pero Yandex las ignora completamente. Esto deberemos tenerlo en cuenta si necesitamos posicionar nuestra web en un buscador en concreto y asegurarnos de que entiende las X-Robots. En caso contrario deberemos buscar alternativas para conseguir una correcta indexación.
Las directivas META robots
Para indicarles a los motores de búsqueda como deben indexar nuestra página utilizaremos una serie de directivas. Las directivas más comunes son las siguientes:
Noindex: Disuadimos a los motores de búsqueda de indexar la página. Gracias a esta etiqueta evitaremos aparecer en los resultados de búsqueda.
Hay que tener en cuenta que los bot deben poder acceder a la página para poder ver la directiva Noindex. Así que si la hemos bloqueado de alguna manera, por ejemplo con la directiva Disallow en el archivo robots.txt, los motores de búsqueda ignorarán completamente la directiva Noindex. Simplemente porque no pueden verla.
Nofollow: Indicamos que no se sigan los enlaces saliente desde
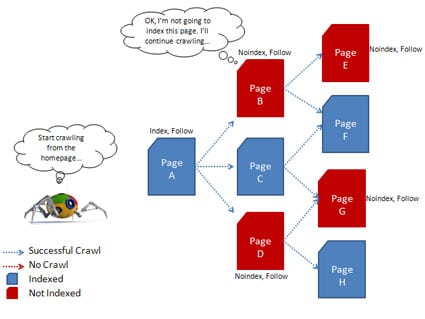 esta página. Es una buena idea utilizarla en aquellas páginas desde las cuales no queramos traspasar “link-juice” como por ejemplo en listados de recursos externos o directorios.
esta página. Es una buena idea utilizarla en aquellas páginas desde las cuales no queramos traspasar “link-juice” como por ejemplo en listados de recursos externos o directorios.Noarchive: No se muestra ningún enlace "en caché" en los resultados de búsqueda. De esta manera evitamos que se pueda acceder a una versión anterior de nuestra página, aunque probablemente el buscador si mantenga una copia en cache de la misma.
Noodp: En las búsquedas la descripción o fragmento que aparece suele ser la META descripción de la página o algún otro contenido relevante de la misma. Pero en ocasiones puede aparecer la descripción de nuestro sitio en el ODP (Open Directory Project). Con esta directiva evitamos que los motores de búsqueda utilicen dicha descripción.
Nosnippet: Evita que los buscadores muestren un fragmento o descripción de la página en los resultados de búsqueda. Unicamente aparecerá el título de la página junto a un enlace a la misma.
All: Permite la indexación y el seguimiento de los enlaces salientes sin límite alguno. Esta directiva es el valor predeterminado y no tiene ningún efecto si se muestra de forma explícita.
None: Equivalente a aplicar simultáneamente las directivas Noindex, Nofollow.
Notranslate: No se ofrece una traducción de esta página en los resultados de búsqueda.
Noimageindex: No se indexan las imágenes de esta página. Cabe mencionar que si dichas imágenes son enlazadas a través de algún otro recurso si serán indexadas. Si realmente queremos evitar la indexación de una imagen será más afectivo añadiendo a la imagen una X-Robots-Tag con Noindex.
Unavailable_after: [RFC-850 date/time]: No se muestra esta página en los resultados de búsqueda después de la fecha y la hora especificadas. La fecha y la hora deben especificarse en el formato RFC 850.
Nocache: Esta directiva tiene los mismos efectos y es equivalente a la directiva noarchive.
Debemos tener claro que no todos los motores de búsqueda entienden las mismas directivas. A continuación presentamos una comparativa con las diferentes directivas explicadas y su utilización por parte de Google, Bing y Yandex.
BUSCADOR
DIRECTIVAS
Bing
Yandex
Noindex
Si
Si
Si
nofollow
Si
Si
Si
noarchive
Si
Si
Si
noodp
Si
Si
No
nosnippet
Si
Si
No
all
Si
No
Si
none
Si
No
Si
notranslate
Si
No
No
noimageindex
Si
No
No
unavailable_after: [RFC-850 date/time]
Si
No
No
nocache
No
Si
No
Podemos ver como los tres buscadores únicamente tienen en común las directivas Noindex, nofollow y noarchive. Siendo Google el que acepta un abanico más amplio de directivas.
Esto deberemos tenerlo en cuenta a la hora de elaborar nuestra estrategia. Si por ejemplo nuestro principal mercado es Rusia, vamos a querer posicionarnos adecuadamente en Yandex. Y debemos saber, por ejemplo que el uso de noimageindex no va a impedir que Yandex indexe las imágenes de la página.
¿Como se utilizan las META Robots?
A la hora de definir las etiquetas META robots nos encontraremos con dos atributos esenciales.
Por un lado tenemos el atributo Name que nos permite indicar a que bot debe afectar el resto de la etiqueta. Para dar instrucciones a todos los buscadores deberemos establecer “robots” como valor del atributo name. Así por ejemplo si queremos que la página no sea indexada por ningún buscador deberemos indicar:
<meta name=”robots” content=”noindex”>
Si en cambio nos queremos dirigir a un bot específico deberemos indicar en name el bot concreto al que nos queramos referir. En el siguiente ejemplo evitaremos que la página sea indexada por Google pero permitiremos que si lo sea por los demás buscadores:
<meta name=”Googlebot” content=”noindex”>
Si queremos indicar directivas diferentes para diferentes motores de búsqueda, lo más apropiado es indicar una META etiqueta diferente para cada uno de ellos. Y no utilizar en ninguna el valor “robots”. De otra manera podemos provocar que la directiva no sea correctamente interpretada.
Así por ejemplo sería correcto indicar:
<meta name=”Googlebot” content=”noindex, noarchive”><meta name=”bingbot” content=”noindex”>
Pero en cambio no sería apropiado utilizar:
<meta name=”Googlebot” content=”noindex, noarchive”><meta name=”robots” content=”noindex”>
El otro atributo que utilizaremos en las META etiquetas robots es content. Dentro de content indicaremos las directivas que deben ser obedecidas por los motores de búsqueda.
Si queremos indicar varias directivas dentro de la misma META etiqueta lo único que deberemos hacer es separarlas por coma. Es indiferente que utilicemos espacios o no al separarlas, de tal forma que en el siguiente ejemplo las dos META etiquetas quieren decir lo mismo:
<meta name=”robots” content=”noindex,nofollow”><meta name=”robots” content=”noindex, nofollow”>
Por norma general los motores de búsqueda entenderán estas directivas de la misma manera independientemente de que se utilicen mayúsculas, minúsculas o cualquier combinación de ambas.
Así por ejemplo es lo mismo:
<meta name=”ROBOTS” content=”NOINDEX,NOFOLLOW”>
que escribir
<meta name=”robots” content=”noindex,nofollow”>
Como ya hemos comentado anteriormente, toda esta información también se puede especificar gracias a las X-Robots-Tag en una cabecera HTTP. De esta manera si queremos evitar la indexación del contenido y que no se sigan enlaces entrantes deberíamos tener una cabecera como la siguiente:
X-Robots-Tag: noindex, nofollowUn detalle importante es que las directivas indicadas en las X-Robots no tienen una mayor jerarquía que las indicadas en las META etiquetas. Los buscadores tenderán a emplear la más restrictiva de ambas. Así que si por ejemplo, indicamos en la cabecera la X-Robots del ejemplo anterior y en la META indicamos:
<meta name=”robots” content=”noindex”>
los motores de búsqueda tenderán a aplicar tanto la directiva Noindex como la directiva nofollow. De esta forma estarían aplicando el criterio más restrictivo.
Las X-Robots-Tag en apache pueden ser especificadas tanto en el archivo .htaccess como en el archivo httpd.conf mediante expresiones regulares. Un ejemplo sería el siguiente:
<Files ~ ".pdf$">Header set X-Robots-Tag "noindex, nofollow"</Files>
Consejos sobre el uso de las META tag robots
En primer lugar aconsejaría únicamente utilizar (en la medida de lo posible) las directivas noindex, nofollow, noarchive, noodp y nosnippet. En primer lugar porque son las que tienen en común Bing y Google y además son las más ampliamente aceptadas por los demás buscadores. En segundo lugar porque en la mayor parte de los casos no necesitareis emplear las demás directivas.
Por ejemplo, en vez de utilizar none es mejor el uso combinado de noindex y nofollow. Si utilizamos none es posible que muchos buscadores no entiendan lo que pretendemos.
La directiva all permite el rastreo de la página. Pero eso es precisamente lo que van a hacer los bot si no les indicamos lo contrario, rastrear la página y sus enlaces salientes. Por lo tanto, su uso es superfluo.
La directiva nocache es equivalente a la directiva noarchive, siendo el uso de esta última más recomendable al estar más extendida.
Por último, y como ya comentamos más arriba, si no queremos indexar una imagen es más efectivo indicarlo con una X-Robots sobre el propio archivo antes que utilizar la directiva noimageindex.
En segundo lugar debemos tener en cuenta que si bloqueamos el acceso a una página a través del archivo robots.txt, de nada nos servirá las directivas que indiquemos en la etiqueta META robots. Esto es así porque los bot lo primero que hacen es leer lo que indica el archivo robots.txt. Si este les disuade de acceder a la página no van a poder ver su contenido.
Así pues, si queremos evitar que un buscador indexe nuestra página debemos hacerlo vía la META etiqueta Noindex y permitiendo el acceso a la misma en el robots.txt.
En tercer lugar debemos ser coherentes a la hora de emplear las directivas en nuestra página. Si indicamos directivas diferentes en las etiquetas META a las que indicamos en las cabeceras HTTP mediante las X-Robots-Tag, podemos provocar confusión en los bot.
La mejor manera de asegurarnos un buen rastreo de nuestra página es siendo coherentes y empleando tan sólo aquellas directivas que necesitemos. Recomendaría emplear as etiquetas META en los documentos html, xhtml y similares evitando en los mismos el uso de X-Robots-Tag. Exclusivamente utilizaría las X-Robots-Tag en los demás archivos en los cuales queramos indicar directivas.
Consideraciones Finales
Tanto las etiquetas META robots como las cabeceras X-Robots-Tag cumplen una función equivalente. Nos permiten, de una forma muy eficiente, indicarle a los motores de búsqueda como deben indexar nuestro contenido y presentarlo en las SERP.
Pero no debemos olvidar que nuestro principal esfuerzo debe ir encaminado a la indexación de los contenidos. Si bien todo lo expuesto supone de gran ayuda en este sentido, un error grave nos puede salir realmente caro.
En definitiva debemos utilizarlas cuando realmente las necesitamos, conociendo el efecto deseado y sin abusar de las mismas. Y por supuesto, si necesitas a un profesional SEO para definir tus etiquetas META robots, no dudes en ponerte en contacto conmigo.




